
Use of neural networks for time series forecasting
22 December 2021
How the AI revolution is changing business
19 January 2022
Use of neural networks for time series forecasting
22 December 2021How the AI revolution is changing business
19 January 2022Convolutional networks
An increasing amount of data is stored as time series: stock market indexes, climate data, medical tests, etc. There are many regression methods for time series. Most of them consist of two main stages: at the first stage, we either use some algorithm to measure the distance between the time series we want to study (DTW, for example, is very popular) or we use any methods to change the representation of the time series and represent them as feature vectors. In the second stage, we use some algorithm to forecast future values of the time series. This can be anything from k-nearest neighbor methods and SVMs to deep neural networks. One thing these methods have in common: they require some kind of feature engineering as a separate step before doing regression analysis. Fortunately, there are models that not only include feature engineering in their nature, but also eliminate the need to do it manually: they are able to extract features and create informative time series representations automatically. These models are convolutional neural networks (CNNs). Studies have shown that using CNNs for time series regression has several significant advantages over other methods. They are highly noise-resistant models and are able to extract highly informative, deep features that are independent of time. The purpose of the convolution operation is to extract high-level features. CNN does not have to be limited to a single convolution layer. Conventionally, the first layer is responsible for capturing low-level features. As more layers are added, the architecture also adapts to high-level features, giving us a network that fully understands the dataset, just as we would.
Imagine a time series of length n and dimensionk. Długość to liczba punktów czasowych, a wymiar to liczba zmiennych w wieloczynnikowym szeregu czasowym. For example, for a weather time series, these could be variables such as temperature, pressure, humidity, etc.
Convolution kernels (kernels) always have the same dimension as the time series, while their length can be variable. In this way, the kernel moves in one direction from the beginning of the time series to its end, performing a convolution. The elements of the kernel are multiplied by the corresponding elements of the time series they cover at any given time. The results of the multiplication are then summed, and a nonlinear activation function is applied to this value. The resulting value becomes an element of a new “filtered” one-dimensional time series, and then the kernel moves forward along the time series to produce the next value. The number of new “filtered” time series is the same as the number of convolution kernels. Depending on the size of the kernel, different aspects, properties, “features” of the initial time series are captured in each of the new filtered series.
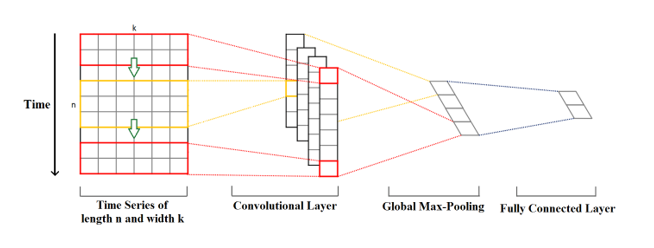
The next step is to apply a pooling operation (max-pooling) to each of the filtered time series vectors: the largest value is taken from each vector. A new vector is created from these values, and this max-pooling vector is the final feature vector, which can be used as input to the regular fully confined layer (fully confined layer).Figure 1. Convolutional network operation.
This article was written thanks to the funds from the European Union’s co-financing of the Operational Program Intelligent Development 2014-2020, a project implemented under the competition of the National Center for Research and Development: under the “Fast Track” competition for micro, small and medium-sized entrepreneurs – competition for projects from less developed regions under Measure 1.1: R&D projects of enterprises Sub-measure 1.1.1 Industrial research and development work carried out by enterprises. Project title: “Developing software to improve forecast accuracy and inventory optimization from the perspective of customer and supplier collaborating in the supply chain using fuzzy deep neural networks.

Related entries

How about AI: what is it and how does artificial intelligence work?
Artificial intelligence (AI) is the ability of machines to exhibit human skills such as learning, inference and recommending solutions. Artificial intelligence enables associations to be made […]

The essence of the classic model of inventory renewal based on the information level – the point of reordering
The main feature of the model based on the so-called. “ordering point,” also known as an information-level ordering system or continuous review [3], is a condition […]
{kind=link}
{kind=link}
{kind=link}
Fuzzy systems
Based on fuzzy sets, a fuzzy inference system can be built. In such a system, fuzzy rules are implemented for modeling, which in turn make it possible to carry out the process of fuzzy inference.