
Rekurencyjne sieci neuronowe
28 stycznia 2022
Istota i znaczenia zapasu zabezpieczającego i jego implikacje z błędami prognoz popytu
3 marca 2022
Rekurencyjne sieci neuronowe
28 stycznia 2022Istota i znaczenia zapasu zabezpieczającego i jego implikacje z błędami prognoz popytu
3 marca 2022Przedziały predykcji jako kwantyfikacja prognoz z wykorzystaniem sieci neuronowej
Przedziały predykcji (PP) oferują wygodny sposób kwantyfikacji niepewności prognoz, dlatego też znalazły szerokie zastosowanie w praktyce prognozowania popytu. PP mogą dostarczyć informacji o najlepszych i najgorszych scenariuszach, umożliwiając decydentom podejmowanie świadomych decyzji w oparciu o cenne informacje na temat nieuniknionej niepewności przyszłości, a także tworzenie odpowiednich planów awaryjnych. Na przykład wąskie PP oznaczają niski poziom niepewności predykcji, budując tym samym zaufanie decydenta do prognoz wykorzystywanych w procesie decyzyjnym, podczas gdy szersze wskaźniki PP mogą zniechęcać do podejmowania decyzji wysokiego ryzyka. Ogólnie rzecz biorąc, jakość PP jest oceniana pod kątem ich szerokości oraz pokrycia w danych historycznych. Wiarygodny, wysokiej jakości PP łączyłby duże pokrycie przyszłych obserwacji z małą – a tym samym informacyjną – szerokością przedziału.
Sieci neuronowe nie są oparte na dobrze zdefiniowanym modelu stochastycznym, dlatego nie jest łatwo wyznaczyć PP dla uzyskanych prognoz. Niemniej jest to możliwe, a do najczęściej wykorzystywanych metod, których można użyć do określenia niepewności prognozy dla nieliniowych modeli uczenia maszynowego należą:
- metoda delty (Delta Method) z zakresu regresji nieliniowej,
- metoda baysowska (Bayesian Method),
- metoda szacowania średniej-wariancji z wykorzystaniem szacunkowych statystyk (Mean-Variance Estimation Method),
- metoda bootstrapowa (Bootstrap Method)
Wspomniane powyżej tradycyjne podejścia najpierw generują prognozy punktowe, a następnie konstruują PP zgodnie z określonymi założeniami dotyczącymi danych lub rozkładu szumu (np. niezależne zmienne o identycznym rozkładzie, szum gaussowski, stała wariancja szumu). Takie restrykcyjne założenia często nie sprawdzają się w rzeczywistych aplikacjach, co powoduje, że PP mogą mieć niskie pokrycie dla testowego zestawu danych lub zbyt konserwatywnie wyznaczone granice.

W literaturze do oceny prognoz punktowych zaproponowano wiele miar związanych z błędami, takich jak średni bezwzględny błąd procentowy (MAPE) i średni kwadratowy błąd (MSE). Oczywiście nie jest możliwa ocena w ten sposób PP. Przegląd literatury wskazuje, że wysiłki badaczy koncentrują się głównie na konstrukcji PP, bez obiektywnej oceny ich jakości pod względem długości i prawdopodobieństwa pokrycia.
Metoda delty opiera się na interpretacji sieci neuronowej jako modelu regresji nieliniowej. To pozwala na wykorzystanie standardowego podejścia asymptotycznego przy konstrukcji PP. Załóżmy, że dana jest sieć ƒ :


Rozwinięcie Taylora pierwszego rzędu pierwszego funkcji (1) wokół prawdziwych wartości parametrów modelu Θ* można zapisać:

W metodzie bootstrapowej przyszłe ścieżki próbek są generowane przy użyciu reszt uzyskanych metodą bootstrapową lub symulacyjną [Hyndman & Athanasopoulos, 2018].
Niech dana będzie sieć neuronowa f dopasowana do danych:
(czyli wszystkie zmienne w tym szeregu mają skończoną taką samą wariancję, najczęściej zakłada się, że błędy mają rozkład normalny).
Można iteracyjnie symulować przyszłe ścieżki wynikające z tego modelu, losowo generując wartość dla ε, z pewnego założonego rozkładu, albo przez ponowne próbkowanie z wartości historycznych.

W ten sposób można iteracyjne uzyskać losową ścieżkę przyszłych wartości prognozowanego szeregu. Wielokrotnie symulując przykładowe ścieżki, budujemy wiedzę o rozkładzie wszystkich przyszłych wartości w oparciu o dopasowaną sieć neuronową. Jeśli zrobimy to kilkaset lub tysiące razy, możemy uzyskać dobry obraz rozkładów prognoz. Niestety to podejście jest zasobo- i czasochłonne. W dodatku wymaga założenia o rozkładzie błędów.
Oprócz powyższych metod można również zastosować podejścia empiryczne. Zauważmy, że po pewnym czasie działania sieci neuronowej mamy już nie tylko historię prawdziwych realizacji szeregów czasowych, ale również historię predykcji uzyskiwanych z modelu (w tym przypadku sieci neuronowej). Możemy zatem uzyskać prawdziwe błędy modelu (reszty) i oszacować przedziały predykcji na tej podstawie (np. wyznaczając odchylenie standardowe reszt i budując przedział predykcji wokół prognozy za pomocą reguły 2 czy 3 sigm).
Oczywiście metoda ta ma problem tzw. „zimnego startu”, czyli nie mamy możliwości jej wykorzystania na początku działania systemu. Zauważmy jednak, że możemy w tej sytuacji wykorzystać standardowe podejście związane podziałem zbioru danych na części (Ripley (1996) – Rysunek 1):
- zbiór uczący (około 70% danych) – na jego bazie wyznaczamy parametry modelu,
- zbiór walidacyjny (około 20 % danych) – na jego bazie tuningujemy hiperparametry modelu (np. liczbę neuronów w warstwach ukrytych sieci neuronowej), co ma zapobiegać przeuczeniu modelu (Rysunek 2),
- zbiór testowy (około 10% danych) – na jego bazie sprawdzamy jakość modelu w pełni nauczonego modelu.
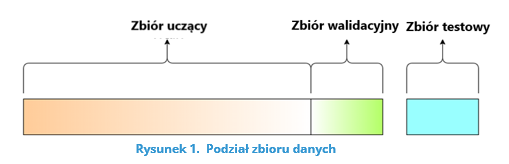
Źródło: https://towardsdatascience.com/train-validation-and-test-sets-72cb40cba9e7 (28.04.2021)
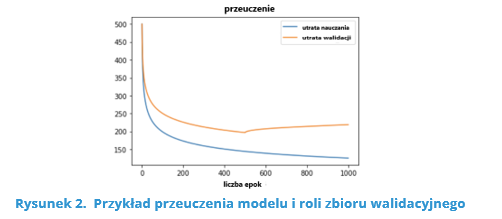
Źródło: https://blog.roboflow.com/train-test-split/ (28.04.2021)
Podane procenty są dość orientacyjne i w dużej mierze zależą od całkowitej liczby obserwacji (Rysunek 3).
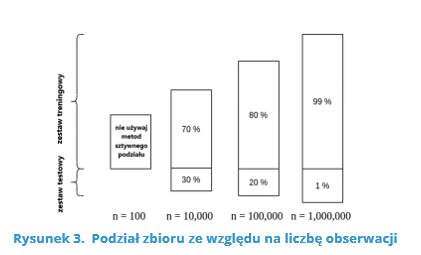
Źródło: https://www.baeldung.com/cs/train-test-datasets-ratio (28.04.2021)
Zauważmy, że w takiej sytuacji możemy wykorzystać oceny uzyskane na zbiorze testowym. Wystarczy porównać je z prawdziwymi wartościami, które zostały zaobserwowane. Pozwala to wyznaczyć reszty modelu i w dalszym kroku oszacować odchylenie standardowe reszt, a co za tym idzie skonstruować przedział predykcji z wykorzystaniem tak oszacowanego odchylenia standardowego, a to możemy wykorzystać do wyznaczenia błędu prognoz w ujęciu klasycznym omówionych w poprzednim artykule.
Źródła literaturowe:
- Hyndman, R. J., & Athanasopoulos, G. (2018). Forecasting: Principles and Practice. (2nd ed.) OTexts. https://otexts.org/fpp2/
- Ripley, Brian D. (1996). Pattern Recognition and Neural Networks. Cambridge University Press.
- https://towardsdatascience.com/train-validation-and-test-sets-72cb40cba9e7 (28.04.2021)
- https://blog.roboflow.com/train-test-split/ (28.04.2021)
- https://www.baeldung.com/cs/train-test-datasets-ratio (28.04.2021)
Niniejszy artykuł powstał dzięki środkom pochodzącym ze współfinansowania przez Unię Europejską Programu Operacyjnego Inteligentny Rozwój 2014-2020, projektu realizowanego w ramach konkursu Narodowego Centrum Badań i Rozwoju: w ramach konkursu „Szybka Ścieżka” dla mikro-, małych i średnich przedsiębiorców – konkurs dla projektów z regionów słabiej rozwiniętych w ramach Działania 1.1: Projekty B+R przedsiębiorstw Poddziałanie 1.1.1 Badania przemysłowe i prace rozwojowe realizowane przez przedsiębiorstwa. Tytuł projektu: „Stworzenie oprogramowania do poprawy trafności prognoz i optymalizacji zapasów z perspektywy odbiorcy i dostawcy współpracujących w ramach łańcucha dostaw przy zastosowaniu rozmytych, głębokich sieci neuronowych.

Powiązane wpisy

D jak Dead Stock
Dead stock, czyli dosłownie martwy zapas, to produkty, które nie znajdują nabywców w oczekiwanym czasie lub w ogóle nie są sprzedawane. Wpływa to negatywnie na efektywność […]

C jak cash to cash cycle
Cykl cash to cash cycle to okres pomiędzy momentem, w którym firma płaci swoim dostawcom za zapasy, a otrzymaniem gotówki od klientów. Koncepcja ta służy do […]

B jak Break-event-point
Metoda punktu równowagi (break-even point) jest narzędziem wykorzystywanym do optymalizacji zapasów w łańcuchu dostaw. Jest to punkt, w którym koszty posiadania zapasów równają się korzyściom z […]